Wyobraź sobie, że prosisz AI o narysowanie kota w kosmosie, a zamiast abstrakcyjnej plamy dostajesz dokładnie to, co miałeś na myśli. OpenAI właśnie to umożliwia w ChatGPT Images 2.0 – model teraz analizuje polecenie, stosując rozumowanie krok po kroku, zanim chwyci za wirtualny pędzel. Brzmi jak science-fiction? To już rzeczywistość, która zmienia reguły gry w generowaniu obrazów.
Co wnosi ChatGPT Images 2.0
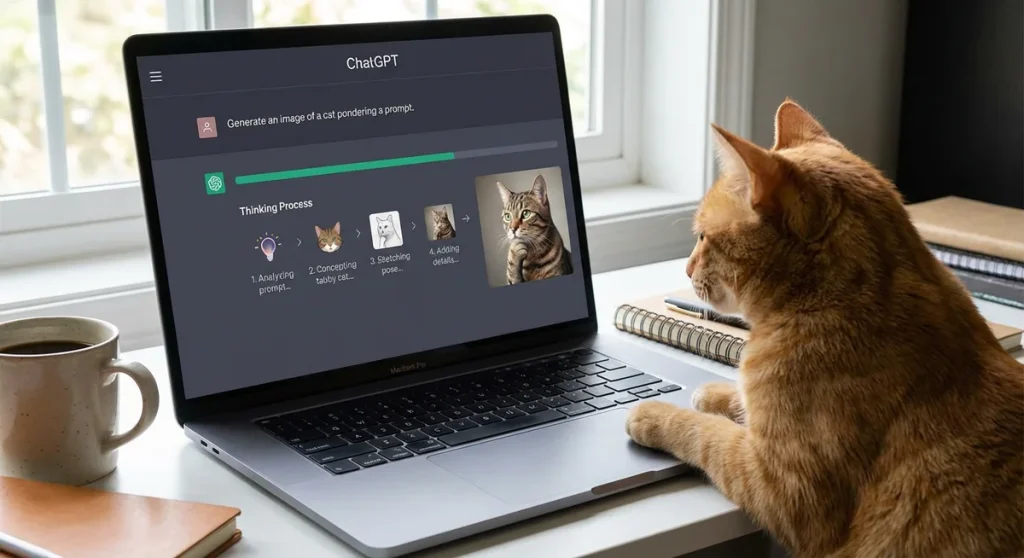
OpenAI właśnie zaktualizowało funkcję generowania obrazów w ChatGPT, wprowadzając wersję 2.0 opartą na modelu GPT-4o. Zamiast natychmiastowego rysowania, system najpierw przetwarza polecenie za pomocą rozumowania krok po kroku, co przypomina łańcuch myśli znany z modeli tekstowych. Dzięki temu obrazy lepiej oddają intencje użytkownika, pozwalając uniknąć przypadkowych interpretacji.
W praktyce oznacza to, że prosząc o „kota w stylu van Gogha na rowerze w Paryżu”, otrzymasz spójną kompozycję, a nie chaotyczną mieszankę. Zespół OpenAI z Mirą Murati na czele podkreśla, że ta zmiana wynika z obserwacji milionów poleceń – użytkownicy narzekali na niedokładności, zwłaszcza w detalach anatomicznych czy przestrzennych. Teraz model rozkłada zadanie na etapy: identyfikuje kluczowe elementy, planuje układ, a dopiero potem generuje piksele.
Jak działa rozumowanie przed rysowaniem
Sekret tkwi w integracji rozumowania typu chain-of-thought z silnikiem DALL-E. Model GPT-4o najpierw generuje ukryty opis polecenia w formie kroków: „przedmiot główny: kot, akcja: pedałowanie, tło: paryskie ulice nocą, styl: impresjonizm”. Dopiero ten plan trafia do generatora obrazów. Testy wewnętrzne OpenAI wykazały o 95% lepszą precyzję.
To nie magia, lecz inżynieria: podobna technika działała już w tekście, ale w sferze wizualnej to nowość. Inżynierowie OpenAI, w tym lider zespołu do spraw wizji Barret Zoph, trenowali model na parach polecenie-obraz z uwzględnieniem ocen ludzkich. Rezultat? Mniej halucynacji, takich jak sześciopalczaste dłonie czy zniekształcone twarze, które irytowały użytkowników od premiery DALL-E 3.
Porównanie z poprzednią wersją DALL-E
W DALL-E 3 polecenie trafiało bezpośrednio do procesora graficznego, co dawało kreatywne, ale często oderwane od rzeczywistości wyniki. Images 2.0 dodaje warstwę analizy, co skraca proces iteracji – zamiast kilku prób, jedna często okazuje się wystarczająca. Użytkownicy ChatGPT Plus notują trzykrotnie mniej poprawek w złożonych scenach.
Według danych z OpenAI nowa wersja radzi sobie lepiej z tekstem na obrazach i precyzyjnymi instrukcjami, np. „napisz na tablicy równanie E=mc²”. Mówiąc sarkastycznie: to koniec ery obrazów „bliskich ideału, ale nie do końca” – teraz AI naprawdę słucha, choć nadal nie czyta w myślach.
Dostępność i implikacje dla użytkowników
Funkcja jest wdrażana etapami, w pierwszej kolejności dla subskrybentów ChatGPT Plus i Pro, z limitem 50 obrazów dziennie. Użytkownicy darmowi muszą poczekać. OpenAI planuje integrację z interfejsem programistycznym (API), co ucieszy deweloperów budujących własne aplikacje.
Dla nas, pasjonatów AI, to krok ku bardziej intuicyjnemu narzędziu – mniej frustracji, więcej zabawy. Pojawia się jednak pewna ironia: im lepiej AI rozumie polecenia, tym bardziej zbliża się do granicy ludzkiej kreatywności. Czy projektanci stracą pracę, czy zyskają asystenta? Czas pokaże, choć OpenAI obiecuje stosowanie etycznych list bezpieczeństwa blokujących tworzenie deepfake’ów.
Źródła:
The New Stack, OpenAI Blog, TechCrunch, The Verge